
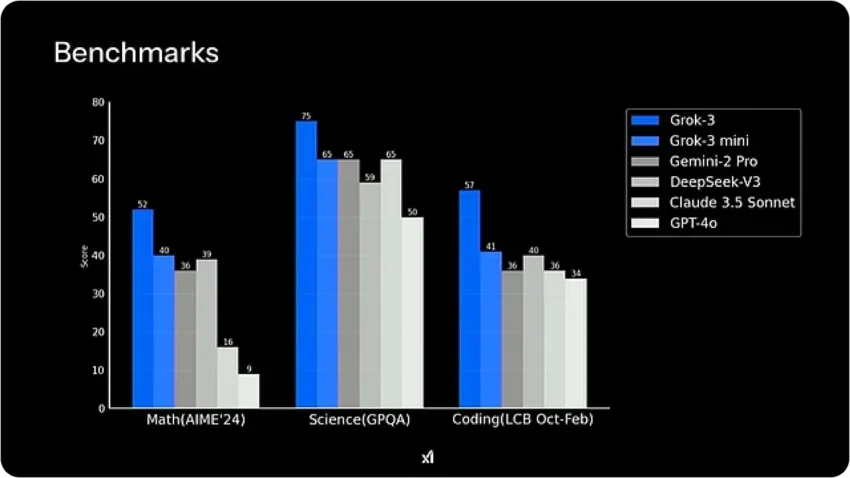
In the rapidly evolving world of artificial intelligence, the race for supremacy often hinges on benchmark results that can make or break a company’s reputation. Recently, a fierce debate erupted over the validity of xAI’s claims regarding its latest model, Grok 3, following accusations of misleading benchmark representations. As accusations and counter-accusations flew between xAI and OpenAI, the intricacies of AI benchmarking came under scrutiny, revealing deeper questions about the metrics used to assess these models. This discourse not only highlights the competitive nature of AI labs but also underscores the complexities and potential pitfalls of interpreting benchmark data, setting the stage for a closer examination of Grok 3’s performance and the implications for the AI landscape.
| Attribute | Grok 3 Reasoning Beta | Grok 3 mini Reasoning | OpenAI o3-mini-high | OpenAI o1 (medium) |
|---|---|---|---|---|
| AIME 2025 Score (@1) | Below o3-mini-high | Below o3-mini-high | Included score | Higher than Grok 3 |
| AIME 2025 Score (cons@64) | Not Provided | Not Provided | Included score | Not Mentioned |
| Validity of Benchmark | Questioned | Questioned | Widely Used | Not Discussed |
| Company Claims | World’s Smartest AI | World’s Smartest AI | Best-Performing Model | Medium Computing Model |
| Disputed Claims | Misleading Chart Accusations | Misleading Chart Accusations | Improved Score Reporting | Scrutiny Suggested |
Introduction to the AI Benchmarking Debate
The world of artificial intelligence is filled with exciting developments, but it also has its fair share of debates. One recent topic of discussion is the benchmarking of AI models, which helps us understand how well they perform. Recently, xAI and OpenAI have been in the spotlight over claims about their AI models’ performance. These discussions are important as they can influence public perception of AI technology.
Understanding benchmarks is crucial because they provide a way to measure how smart an AI model really is. For example, when xAI claimed that its model, Grok 3, performed better than OpenAI’s model, it sparked a heated discussion. This debate shows us how benchmarks can be tricky and sometimes misleading, making it essential to look closely at the information being presented.
What Are AI Benchmarks and Why Do They Matter?
AI benchmarks are tests designed to evaluate how well an AI model can perform specific tasks, like solving math problems. They help developers understand the strengths and weaknesses of their models. By comparing scores from these benchmarks, companies can showcase their models’ capabilities and advancements in AI technology.
However, not all benchmarks are created equal. Some tests may be more challenging or relevant than others. This is why it’s important to question the benchmarks being used. For example, the AIME 2025 exam, used by xAI to promote Grok 3, has faced scrutiny. Experts wonder if it accurately reflects an AI’s true abilities, leading to discussions about which benchmarks are the best indicators of performance.

The Controversy Surrounding Grok 3’s Performance
The debate heated up when xAI shared a graph that suggested Grok 3 outperformed OpenAI’s model. This claim raised eyebrows among AI experts and OpenAI employees. They pointed out that xAI did not include a key metric, called consensus@64, which could significantly alter the comparison. Without this information, it might look like Grok 3 is better than it actually is.
This situation highlights how crucial it is to present benchmarks accurately. When companies share their results, they should include all relevant data to give a complete picture. Transparency is key in helping the public understand the true capabilities of AI models, and misleading graphs can lead to confusion and mistrust among consumers.
The Role of Transparency in AI Reporting
Transparency in reporting AI benchmarks is vital for building trust between companies and users. When companies like xAI and OpenAI share their results, they have a responsibility to present them honestly. If they omit important details, it can mislead the public and affect the reputation of the entire AI field.
Moreover, clear communication about benchmarks helps users make informed decisions. For instance, if customers know how a model truly performs in various tests, they can choose the best AI solution for their needs. This is particularly important as AI becomes more integrated into our daily lives, from smart assistants to educational tools.
The Importance of Comprehensive Metrics
Metrics in AI benchmarking don’t just measure performance; they also reveal insights into the model’s efficiency and effectiveness. For example, while Grok 3 might show impressive scores, understanding how much computing power and money were spent to achieve those scores can provide a deeper understanding of its capabilities.
As AI researchers like Nathan Lambert have noted, knowing the costs associated with achieving benchmark scores is crucial. This information can shed light on whether a model is truly the best choice or if it just looks good on paper. Comprehensive metrics can help guide future developments in AI technology, ensuring advancements are practical and beneficial.
Looking Ahead: The Future of AI Benchmarking
As the field of artificial intelligence continues to grow, the way we evaluate models will likely evolve. New benchmarks may emerge that better reflect real-world applications and challenges. This could lead to more accurate assessments and comparisons of AI capabilities, helping companies improve their models.



Additionally, as discussions about AI ethics and transparency gain traction, we can expect future benchmarks to be more rigorous and reliable. These changes could help ensure that users receive clear and honest information about AI technologies, allowing them to make better decisions as they navigate this rapidly advancing field.
Frequently Asked Questions
What is the controversy surrounding Grok 3’s benchmarks?
The controversy centers on accusations that xAI misrepresented Grok 3’s benchmark scores, specifically omitting important metrics that could alter the perceived performance compared to OpenAI’s models.
What does cons@64 mean in AI benchmarks?
Cons@64 stands for ‘consensus@64,’ allowing a model 64 attempts to answer each problem, boosting scores significantly. Omitting this can misrepresent a model’s true capabilities.
How did Grok 3 perform on the AIME 2025 benchmark?
Grok 3 Reasoning Beta and mini Reasoning scored well on AIME 2025 but fell short when compared to OpenAI’s o3-mini-high at the first attempt score.
Why is AIME 2025 used as a benchmark for AI?
AIME 2025 is a challenging math exam often used to assess AI models’ math abilities, providing a standard for evaluating their performance in solving complex problems.
What are the implications of misleading benchmark reporting?
Misleading benchmarks can create confusion about an AI model’s true capabilities, affecting user trust and decision-making in choosing AI technologies.

What other factors are important when evaluating AI models?
Besides benchmark scores, the computational and monetary costs of achieving those scores are crucial for understanding AI model efficiency and practicality.
How does this debate affect public perception of AI?
Discussions about benchmark accuracy influence public perception, highlighting the need for transparency in AI development and the potential for biases in reporting.
Summary
Recently, a debate arose over the accuracy of AI benchmarks following accusations from an OpenAI employee that xAI misrepresented results for its model, Grok 3. xAI claimed Grok 3 outperformed OpenAI’s best model on a math test, AIME 2025. However, critics pointed out that xAI’s graph omitted a key scoring method, cons@64, which significantly boosts scores. This led to confusion about the models’ true performance. Both companies have faced scrutiny for their benchmark reporting, highlighting the need for transparency in AI evaluations and the importance of understanding the costs involved in achieving these scores.